

AI的火热,除了带动GPU的大红大紫以外,背后的重要存储技术HBM也在过去几年冲上了风口浪尖。最近,SK hynix和三星的业绩和动作标明,HBM在未来大有可为。
据路透社报道,HBM 芯片目前占通用内存市场的 15%,而去年这一比例为 8%。SK 海力士在 HBM 市场拥有最大的市场占有率,由于生成式 AI 热潮刺激了对 Nvidia GPU 的需求,该市场的需求猛增。它是占据 AI GPU 市场 80% 份额的 Nvidia 的 HBM3 内存唯一供应商,并于 3 月份开始量产最新一代 HBM3E。美光和三星等竞争供应商正在开发自己的 HBM 产品,以阻止 SK 海力士主导市场。
而围绕着HBM,厂商们也都各出奇招。除了针对现存技术进行深耕,并围绕未来的HBM 4,悄然吹响进攻号角(关于HBM4,可以借鉴文章《HBM4要来了》)。另外,说明一下,因为笔者没找到美光关于HBM技术的更多介绍,所以本文中就没有谈到他在HBM技术的展望和分享,希望我们大家补充。
据SK hynix所说,目前,封装技术已超越了“将芯片电气连接,并保护芯片免受外部冲击”的传统作用,而是成为实现差异化产品性能的重要技术。SK海力士HBM以硅通孔技术(TSV:Through Silicon Via)、批量回流模制底部填充(MR-MUF:Mass Reflow-Molded Underfill)先进封装工艺作为核心技术,赢得了卓越的市场声誉。

其中,TSV技术常见,而在MR-MUF中,批量回流焊(MR)是通过融化堆叠芯片之间的凸块,让芯片互相连接的技术。模塑底部填充(MUF)是在堆叠的芯片之间填充保护材料来提升耐久性和散热效果的技术。使用MR-MUF,则可同时封装多层 DRAM。

具体而言,从技术上流程看,在 DRAM 下方,有连接芯片的铅基“凸块”。MR 技术涉及加热并同时熔化所有这些凸块以进行焊接。连接完所有 DRAM 后,接下来会进行称为 MUF 的过程来保护芯片。注入以优异散热性而闻名的环氧密封剂来填充芯片之间的间隙并将其封装。然后通过加热和加压使组件硬化,从而完成 HBM。
SK海力士将这一过程描述为“像在烤箱中烘烤一样均匀地施加热量,并一次粘合所有芯片,使其稳定且高效。
在最近的一篇博客中SK hynix高管表示,为适应AI时代的需求,SK海力士专注于开发‘标志性存储产品’以实现用户对于性能、功能、尺寸、形态、功效等方面的差异化需求。为实现这一目标,公司正在推进TSV和MR-MUF的技术发展,这些技术在HBM性能中发挥着关键作用。
值得一提的是,虽然MR-MUF被普遍的使用,我们不得已承认,MR-MUF 拥有容易翘曲、导致晶圆末端弯曲、空洞现象(即保护材料在某些区域分布不均匀)也会对 MR-MUF 的可靠性产生负面影响等缺点。但SK hynix表示,与HBM开发初期相比,他们成功地减少了翘曲现象,目前我们正在开发克服这一问题的技术。下一步,抉择会聚焦在减少空隙。
SK hynix高管强调,公司旨在实现‘超越HBM的封装技术’任务。如他所说,短期内,我们的主要目标是扩大在韩国国内的产能,以应对HBM市场的需求,同时我们也要充分的利用全球各地的生产基地,实现收益最大化。从长远来看,正如当前作为HBM核心工艺的MR-MUF技术一样,确保开发创新的先进封装技术是我们的目标。
此外,SK hynix还致力于芯粒(Chiplet)及混合键合(Hybrid bonding)等下一代先进封装技术的开发,以支持半导体存储器和逻辑芯片之间的异构集成,同时促进新型半导体的发展。当中,Hybrid bonding也是被看作是HBM封装的又一个新选择。但根据之前的计划不一样,SK海力士打算在下一代的HBM 4中持续采用尖端封装技术MR-MUF。作为替代方案而出现的混合键合技术预计由于 HBM 标准的放宽而缓慢引入。

在日前的一场技术大会上,SK hynix分享道,下一代封装技术正朝着存储器、逻辑和控制器融合的方向发展,比如2.5D,SK海力士也在使用这一些技术使 HBM 更加稳健。
在谈到HBM未来的时候,SK Hynix认为,市场将更倾向于专业化(Specialized)和定制化(Customized)产品,以实现用户需求。他强调,对于新一代HBM,卓越的性能是门槛,同时,还须具备满足多种客户的特定需求、超越传统存储器性能的优势。
此外,SK 海力士公司早前还与台积电 (TSMC) 签署谅解备忘录 (MoU),合作开发下一代 HBM,并通过先进封装技术增强逻辑和 HBM 集成。
该公司计划通过这一举措继续开发 HBM4,即 HBM 系列第六代产品,预计将于 2026 年开始量产。
SK海力士表示,AI存储领域的全球领导者与台积电的合作将带来HBM技术的更多创新。此次合作还有望通过产品设计、代工厂和内存提供商之间的三边合作实现内存性能的突破。
两家公司将首先专注于提高安装在 HBM 封装最底部的基础芯片的性能。HBM 的制作的过程是将核心 DRAM 芯片堆叠在采用 TSV(硅通孔)技术的基础芯片之上,并使用 TSV 将 DRAM 堆栈中的固定数量的层垂直连接到具有 TSV 的核心芯片,形成 HBM 封装。位于底部的基础芯片连接到控制 HBM 的 GPU。
SK海力士已使用专有技术制造高达HBM3E的基础芯片,但计划在HBM4基础芯片上采用台积电的先进逻辑工艺,以便可以将附加功能封装到有限的空间中。这也有助于 SK 海力士生产定制 HBM,实现用户对性能和功效的广泛需求。
SK海力士和台积电还同意合作优化SK海力士的HBM和台积电的CoWoS(基板上晶圆芯片)技术的集成,同时合作响应常见客户与HBM相关的要求。
SK 海力士总裁兼 AI 基础设施负责人Justin Kim表示:“我们大家都希望与台积电建立强有力的合作伙伴关系,以帮助加快我们与客户的开放合作,并开发业界性能最佳的 HBM4。” “通过此次合作,我们将通过增强定制内存平台领域的竞争力,进一步巩固我们作为整体人工智能内存提供商的市场领导地位。”
“多年来,台积电和 SK 海力士已经建立了牢固的合作伙伴关系。我们一起努力,整合最先进的逻辑和最先进的 HBM,提供世界领先的人工智能解决方案 。”台积电的Kevin Zhang表示。“展望下一代 HBM4,我们始终相信我们将继续密切合作,提供最佳集成解决方案,为我们的共同客户开启新的AI创新。”
从技术上看,这是一种与MR-MUF略有不同的技术。在每次堆叠芯片时,都会在各层之间放置一层不导电的粘合膜。该薄膜是一种聚合物材料,用于使芯片彼此绝缘并保护连接点免受撞击。随着发展,三星慢慢地减少了 NCF 材料的厚度,将 12 层第五代 HBM3E 的厚度降至 7 微米 (μm)。该公司表示:“这种方法的优点是可以最大限度地减少随着层数增加和芯片厚度减小而有几率发生的翘曲,使其更适合构建更高的堆栈。”

据三星介绍,TC NCF方法在堆叠更高层方面的优势。但对于这技术而言,优化热量和压力是其成功的关键。因此据报道,三星早前正在与设备制造商进行讨论,以进一步提升其标新。面对SK海力士的竞争,三星电子在全公司范围内集中力量,在2月宣布了“Advanced TC-NCF”技术。该技术能减少 TC-NCF 工艺中必要薄膜的厚度,从而在保持 HBM 高度的同时增加半导体层数。
此外,有消息表示,三星的TC NCF良率不如SK hynix,所以三星电子考虑将MUF材料引入穿硅电极(TSV)工艺中。报道指出,三星还从日本购买了硬化(成型)设备,可以使这种MUF变得坚硬。补充说明一下,SK海力士在第二代HBM之前也使用NCF ,但从第三代(HBM2E)开始改用MUF(特别是MR-MUF)。分析人士更是认为MUF是SK海力士能够在HBM市场脱颖而出的原因,这也是为何有消息指出三星也在寻求开发和引入这项技术。一位熟悉三星情况的半导体行业高管表示,“据我了解,三星正在研究的 MUF 材料与 SK 海力士的技术并不完全相同”。
尔后,三星对此辟谣并强调公司将继续在TC NCF上发力。在日前的一篇博客中,三星更是分享了他们对未来的看法。
在被问到公司当前HBM为何能如此与众不同时,三星强调,公司在AdvancedTC NCF上的见解功不可没。三星方面接着说,HBM 采用 DRAM 芯片的垂直堆叠(例如 8H 和 12H)来提高容量和带宽。然而,不同代的 HBM 都遵循预定的整体厚度。在这种限制下,随着附加层的堆叠,负责数据存储的核心裸片不可避免地会变得更薄,这可能会给组装带来挑战,导致芯片翘曲或破裂,以及热阻增加。
在三星看来,HBM 的热阻主要受芯片间距的影响,而三星有着先进的高密度堆叠芯片控制技术,减少芯片之间NCF材料的厚度,并利用热压缩技术使芯片更加紧密。这种创新方法实现了业界最小的 7 微米 (um) 芯片间距。此外,在芯片键合过程中,三星策略性地设计了需要信号传输的小凸块和散热至关重要的大凸块。这种优化增强了散热和产量。此外,应用工艺技术在有限的封装尺寸内最小化单个 DRAM 芯片的尺寸,确保了卓越的量产能力和可靠性,从而提供了显着的竞争优势。
三星同时谈到,业界越来越认识到,处理器和内存公司各自优化其产品的孤立努力不足以释放 AGI 时代所需的创新。因此,“定制 HBM”成为潮流,这也代表了实现处理器和内存之间协同优化以加速这一趋势的第一步。为此,三星利用其在内存、代工、系统LSI和先进封装方面的综合能力。此外,三星还为下一代 HBM 建立了专门的团队,利用公司无与伦比的能力,我们致力于在塑造未来方面做出重大改变。
在谈到未来的规划时,三星表示,HBM 市场仍处于早期阶段,预计将迅速发生明显的变化,公司的策略是通过预测市场发展并提前主动规划和开发必要的产品来保持领头羊。随着 HBM 市场的成熟,三星预计三个重大变化将重塑该行业:
首先,“细分”。在 HBM 的早期,硬件需要具有多功能性。然而,随着服务围绕杀手级应用持续不断的发展,硬件基础设施将不可避免地针对每个特定服务来优化。为了应对这一趋势,三星将提供一系列封装选项(8H、12H 和 16H)和基础芯片变体,同时标准化核心芯片。
其次,处理器和内存之间的协同优化将需要更高程度的定制。为了应对这一挑战,三星将利用创建平台来最大限度地利用 HBM 解决方案中的通用设计元素,并建立一个高效的系统,通过扩大我们的ECO合作伙伴关系来满足定制请求。
第三,为客服“电源墙”,处理器和内存之间的距离将变得更近。第一个创新在 HBM4 中很明显,它在其基础芯片中采用了逻辑处理技术。第二项创新是随着当前 2.5D 到 3D HBM 架构的转变而发生的,而第三项创新涉及集成 DRAM 单元和逻辑,这是设计 HBM-PIM 的方法。在积极规划和准备引领市场的同时,三星已开始与客户和合作伙伴进行讨论,以将这些创新变为现实。
三星强调,随着 HBM 作为生成式 AI 最优化内存解决方案的地位变得毋庸置疑,许多客户和数据中心正在迅速采用它。然而,确保人工智能服务不间断至关重要。,即使是一个有缺陷的芯片也可能会产生灾难性的影响。因此,确保 HBM 质量的设计和测试技术势在必行。此外,开发能够逐步降低功耗并提高系统能效的 HBM 设计结构也至关重要。
为此,三星计划通过针对高温环境优化的NCF组装技术和尖端工艺技术,将16H技术融入下一代HBM4中。据三星的规划,HBM 4将在2025年生产样品。
不过,三星副总裁 Kim Dae-woo 早前在韩国一个会议上表示,三星正在考虑在HBM 4中使用混合键合或NCF,,并于2026年开始量产。混合键合更具优势,因为它们能紧凑地添加更多堆叠,而无需使用填充凸块进行连接的硅通孔 (TSV)。使用相同的技术,HBM 上的核心芯片 DRAM 也可以变得更厚。
Kim 还表示,在最多 8 个堆叠时,MR-MUF的生产效率比 TC-NCF 更高,但一旦堆叠达到 12 个或以上,后者将具有更多优势。该副总裁还指出,当 HBM4 推出时,定制请求预计会增加。他补充说,缓冲芯片将变为逻辑芯片,因此芯片可以来自三星或台积电。
有报道还指出,英伟达还将采用三星的技术,做HBM的封装,这对于这家韩国巨头来说,是另一个好消息。
在北美技术研讨会上,该公司推出了下一代晶圆系统平台——CoW-SoW——该平台将实现与晶圆级设计的 3D 集成。该技术建立在台积电 2020 年推出的 InFO_SoW 晶圆级系统集成技术的基础上,该技术使其可构建晶圆级逻辑处理器。到目前为止,只有特斯拉在其 Dojo 超级计算机中采用了这项技术,台积电表示该计算机现已投入生产。
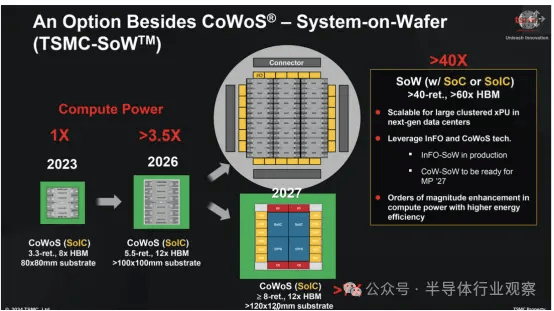
在即将推出的 CoW-SoW 平台中,台积电将在其晶圆系统平台中合并两种封装方法——InFO_SoW 和集成芯片系统 (SoIC)。利用晶圆上芯片 (CoW) 技术,该方法将能够将存储器或逻辑直接堆叠在晶圆上系统之上。新的CoW_SoW技术预计将在2027年实现大规模生产,但实际产品何时上市还有待观察。
据了解,台积电的CoW-SoW专注于将晶圆级处理器与HBM4内存集成。这些下一代内存堆栈将采用 2048 位接口,这使得将 HBM4 直接集成在逻辑芯片顶部成为可能。同时,在晶圆级处理器上堆叠额外的逻辑以优化成本也可能是有意义的。
“因此,在未来,使用晶圆级集成[将允许]我们的客户将更多的逻辑和存储器集成在一起,”台积电业务开发副总裁Kevin Zhang说。“SoW 不再是虚构的;我们已与客户合作生产一些已经到位的产品。我们大家都认为,通过利用我们先进的晶圆级集成技术,我们大家可以为客户提供很重要的产品使他们可以继续增强能力,为他们的人工智能集群或[超级计算机]引入更多计算、更节能的计算。”

一般而言,晶圆级处理器(即 Cerebras 的 WSE),特别是基于 InFO_SoW 的处理器,可提供显着的性能和效率优势,包括高带宽和低延迟的核心到核心通信、低功率传输网络阻抗以及高能源效率。作为额外的好处,此类处理器还具有“额外”核心形式的额外冗余。
然而,InFO_SoW技术有一定的局限性。例如,使用这种方法制造的晶圆级处理器完全依赖于片上存储器,这可能没办法满足未来人工智能的需求(但目前来说很好)。CoW-SoW 将解决这一个问题,因为它将允许将 HBM4 放置在此类晶圆上。此外,InFO_SoW晶圆采用单节点加工,该节点不支持3D堆叠,而CoW-SoW产品将支持3D堆叠。

